The natural follow-up question, once you’ve used LoRA enough, is: why do all layers get the same rank?
Empirically, transformer layers don’t contribute equally to whatever you’re fine-tuning on. Some are doing heavy lifting; some are barely moving. So if you have a fixed parameter budget, why not concentrate it where it matters?
This question kicked off an entire subfield of “adaptive rank allocation” methods over the past two years — and the punchline of every paper has been the same. Profile the gradients, allocate rank where the gradients are largest, save parameters, get the same accuracy. AdaLoRA. GoRA. IGU-LoRA. ILA. Aletheia. Five different angles on the same recipe, all under supervised fine-tuning, all reporting the same kind of win.
So I tried the recipe under GRPO — the RL algorithm DeepSeek popularized for training reasoning models.
It didn’t transfer. Adaptive allocation made the model worse than uniform.
This post is about why. The short version is that the gradient structure of GRPO is qualitatively different from SFT — flatter, more spread out, and more entangled with rank itself — and a recipe that depends on a peaked, sparse importance map quietly stops working when the importance map isn’t peaked or sparse anymore. The longer version has a surprise in it that has uncomfortable implications for the entire profile-then-reallocate paradigm.
The adaptive-rank story under SFT
Quick recap of the supervised case, because the rest of this post hinges on the contrast.
The original LoRA paper (Hu et al., 2022) set rank uniformly across layers. Every adapter got, say, rank 8 or 16, regardless of what layer it was attached to. This was a reasonable default — you’re already saving 99% of parameters, so optimizing the last bit isn’t a priority.
AdaLoRA (Zhang et al., 2023) was the first major paper to push back on this. The argument: not all weight updates matter equally during fine-tuning, so under a fixed parameter budget, you should pour rank into the high-importance directions and prune it away from the low-importance ones. AdaLoRA does this dynamically during training, parameterizing the LoRA decomposition as an SVD and pruning the small singular values as it learns which ones matter.
The key empirical finding behind AdaLoRA, and behind everything that followed, is that the importance distribution is peaked. Some layers and modules carry a lot of signal; others carry almost none. If you visualize the per-layer gradient magnitude during SFT, you see hot spots — usually concentrated in middle-to-late attention layers — and cold zones where the gradient is essentially noise.
ILA (Shi et al., 2024) made this concrete in a clean way: under SFT, roughly 30% of layers carry over 80% of the gradient signal. The rest are essentially passengers. Reduce their rank, redistribute that capacity into the hot layers, and you get the same downstream accuracy with a smaller parameter count. This is the free lunch that adaptive rank allocation has been compounding for two years.
GoRA (He et al., 2025) extended the idea to dynamic during-training profiling rather than static profiling. IGU-LoRA (Cui et al., 2026) added a per-layer initialization variance correction so that adapters with different ranks start with comparable activation magnitudes. Aletheia (Saket, 2026) brought in a more rigorous information-theoretic objective on top of the same skeleton.
Different angles on the same recipe. Distilled, the recipe is:
- Profile the per-layer gradient magnitude during a uniform-rank run.
- Allocate rank proportional to gradient importance, under a fixed total budget.
- Train.
- Win on the parameter-accuracy frontier.
This works because the gradient signal under SFT is sparse. Take that sparsity away and the recipe loses its purchase.
What changes under RL
GRPO — Group Relative Policy Optimization, from the DeepSeekMath paper — looks superficially like another fine-tuning algorithm. You take a base model, compute per-token gradients, update the weights. The gradient just comes from a different objective: instead of cross-entropy against ground truth, you compute a reward over generated completions and shape the gradient using group-relative advantages.
So the natural question is: does the SFT recipe transfer? Profile the gradients during a GRPO run, redistribute rank where the gradients are large, train, save parameters?
The setup of the experiment was deliberately boring. Qwen 2.5 1.5B Instruct. GSM8K. GRPO with two rewards (format compliance and correctness). LoRA on all seven projection modules per layer (q/k/v/o/up/down/gate) — 28 layers × 7 modules = 196 adapters in total. Total rank budget held fixed at 896 across configurations (= 28 × 32, the uniform baseline) so every configuration had the same parameter count. The only thing varying was where that parameter mass was concentrated.
The strategies tested:
- Uniform — every layer rank 32. Baseline.
- Proportional — gradient-aware. Hot layers get more rank, cold layers get less. Same total budget.
- Reduced 70% — gradient-aware at 70% of the parameters. (How much budget can the recipe save?)
- Random — same total budget, allocation drawn at random. Control.
I expected the standard SFT result: proportional ≥ uniform > random. What I got was:
| Strategy | Rank Range | Params | GSM8K Acc |
|---|---|---|---|
| Base model (no LoRA) | — | 0 | 66.0% |
| Reduced 70% | r=12–31 | 25.8M | 65.0% |
| Random | r=16–48 | 36.9M | 67.5% |
| Proportional (gradient-aware) | r=20–40 | 36.9M | 70.0% |
| Uniform (r=32) | r=32–32 | 36.9M | 74.5% |
Uniform won. By 4.5 points over the gradient-aware proportional allocation that “should” have been the optimum.
The interesting twist: gradient-aware did beat random by 2.5 points. The gradient signal was real — proportional knew which layers were hotter than random did. It just wasn’t enough to overcome the cost of redistributing rank.
Why: GRPO has a flatter gradient landscape
The first thing that came out of profiling was that the gradient distribution under GRPO looks nothing like the SFT story.
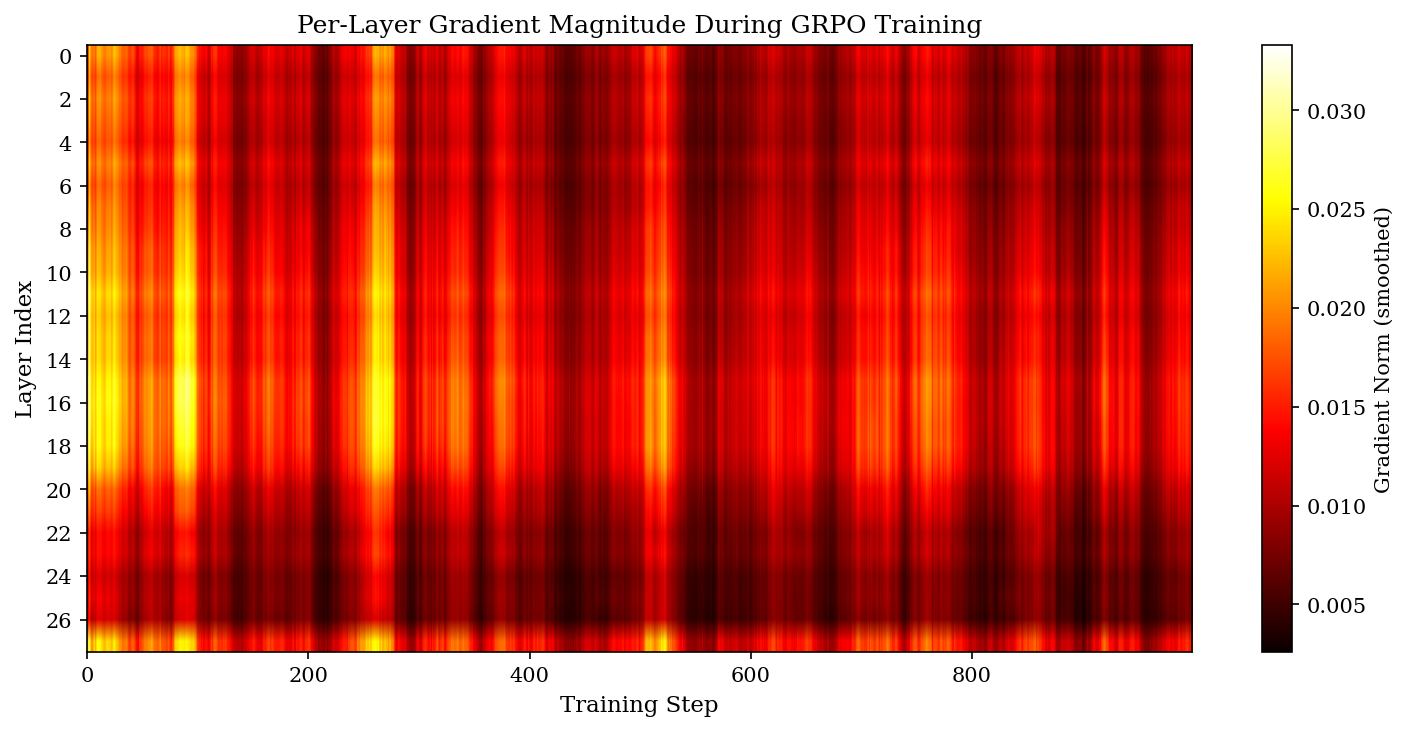
Under SFT (per ILA’s findings), the top 30% of layers carry over 80% of the gradient signal. Under GRPO in this run, the top 30% carry only ~36%. The hottest layer (15) carries 4.68% of total gradient. The coldest (26) carries 2.15%. Max-to-min ratio: 2.17x.
For comparison, SFT fine-tunes on similar architectures often show ratios of 10x or more. GRPO is essentially flat.
The flatness isn’t an artifact of averaging over noisy phases either. The early-vs-late training correlation of the importance map is 0.962 — it stabilizes within the first 100 steps and stays put. The structure is real, it’s just shallow.
This already gives you a clean story for the negative result. Adaptive rank allocation banks on the existence of idle layers whose capacity you can safely steal. Under SFT there are. Under GRPO there aren’t. Drop a layer’s rank from 32 to 20 and you’ve broken something the model needs.
But there was a second thing that came out of the profiling that I didn’t expect.
The amplification effect
I’d profiled gradients during every run, not just the uniform baseline, mostly to sanity-check that the rank allocation was applied correctly. When I plotted the gradient distribution for the proportional run alongside uniform:
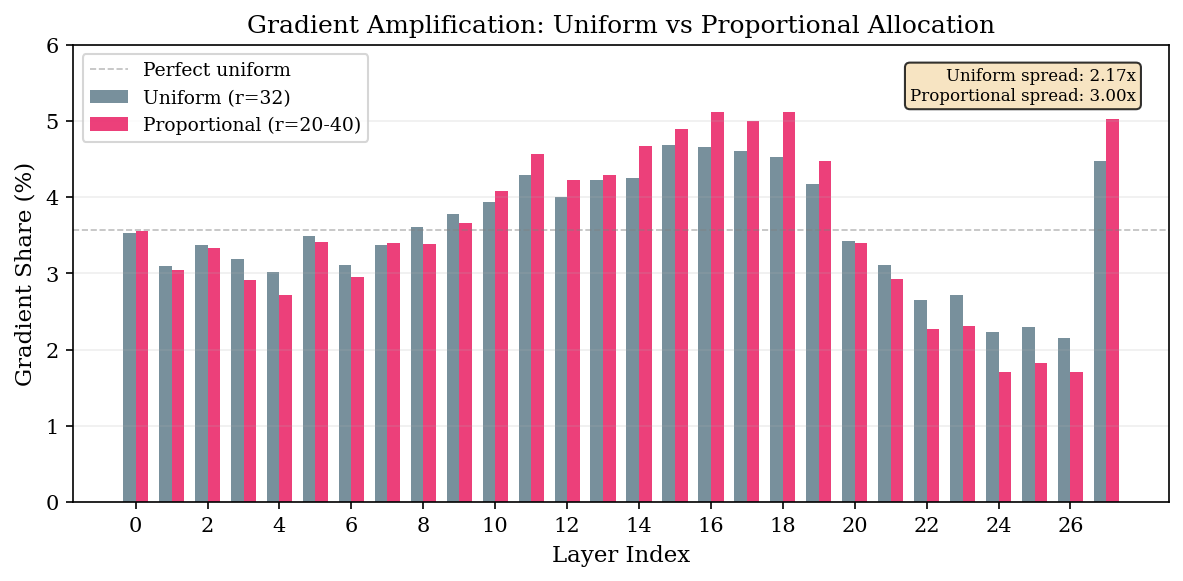
The spread widens. Uniform: 2.17x max/min. Proportional (same total budget): 3.00x. Reduced: 3.57x.
Hot layers given more rank absorbed more gradient. Cold layers given less rank went quieter. The allocation was creating a positive feedback loop — rank was concentrating gradient onto whichever layers had been given the rank.
That made me suspicious. Was the gradient just following itself? Was the proportional configuration simply amplifying its own profiling?
I ran the random allocation as a control. Layer 1 is normally one of the coldest layers — 3.09% of gradient under uniform. The random allocation gave it rank 48. Its gradient share jumped to 4.21%, making it the second hottest layer in the network. Layer 15, normally the hottest, got rank 24 in the random allocation, and its gradient share dropped from 4.68% to 3.98%.
The correlation between allocated rank and gradient shift is 0.972 for random, 0.946 for proportional.
Read that line again. Even when rank is allocated with no relation to gradient importance whatsoever, the gradient follows. Rank determines gradient importance, not the other way around.
This is the part of the result I didn’t expect, and it has uncomfortable implications for the entire profile-then-reallocate paradigm. The “important” layers your profiler identifies aren’t intrinsically important. They’re whatever layers happen to have rank to express themselves through. Move the rank, and the importance map moves with it.
This doesn’t necessarily falsify what the SFT papers found — under SFT, the importance map appears to be more anchored in the data and less in the rank distribution. But the moment you move to RL, where the gradient is shaped by sparse, noisy reward signals rather than dense supervision, the relationship inverts. Rank becomes a cause of importance, not a consequence.
A practical aside: PEFT’s silent wildcard
Halfway through this work, my proportional run had 34.6M params instead of the expected 36.9M and no errors were thrown. Worth flagging because if you’re doing non-uniform LoRA in PEFT, you will hit this.
I had set up rank_pattern like this:
rank_pattern = {
"model.layers.15.*.q_proj": 40,
...
}
PEFT’s rank_pattern does not treat * as a glob. It’s a regex match against the full module path, and * in regex means “zero or more of the previous character.” So model.layers.15.*.q_proj matched essentially nothing in the actual module tree, every match silently fell back to the default rank, and the only signal anything was wrong was a slightly-off parameter count.
Fix: use exact paths.
rank_pattern = {
"model.layers.15.self_attn.q_proj": 40,
"model.layers.15.mlp.up_proj": 40,
...
}
Verify trainable parameter count after applying the config.
What I’d take from this
Don’t naively port SFT-era rank allocation to RL training. SFT and RL appear to have qualitatively different gradient structures — peaked under SFT, flat under GRPO — and the techniques that exploit one don’t transfer. This is true even when the algorithm “looks like” fine-tuning at the gradient-step level.
The amplification finding has a stronger implication: static profiling can’t be the answer for RL. Whatever you measure during a uniform-rank run will shift the moment you reallocate. If adaptive rank is going to work under RL — and it might — it probably has to be dynamic, adjusting continuously during training (the AdaLoRA way), rather than committing to a fixed allocation upfront based on a profiling run.
The good news is that under GRPO, uniform is fine. It’s also the cheapest thing to do. If you’re allocating effort across an LLM training stack, you can move rank-allocation work down the priority list for RL workloads and spend the cycles somewhere they’ll actually pay off.
Negative results don’t always make great paper material. But this one was clarifying for me about what “transfer” actually means between fine-tuning regimes — and about how much of what we think we know about which layers matter is downstream of capacity allocation rather than upstream of it.
The full paper is on arXiv (cs.CL, awaiting announcement). Code: github.com/yashsawant22/adaptive-lora-rank-grpo. Submitted to the CoLoRAI workshop at ICML 2026.
]]>