Gradient-Based LoRA Rank Allocation Fails in GRPO
Adaptive rank allocation for LoRA — giving more capacity to layers that “matter” and less to layers that don’t — is one of those ideas that keeps getting validated. AdaLoRA, GoRA, IGU-LoRA, Aletheia, ILA — every recent paper says the same thing: profile the gradients, allocate rank where the gradients are large, save parameters, get the same accuracy.
So I did the obvious thing: ran the same recipe under GRPO instead of supervised fine-tuning, expecting a clean transfer.
It didn’t work. Adaptive allocation made the model worse than uniform.
This post is what I found, why I think it happens, and a debugging story along the way.
The setup
- Model: Qwen 2.5 1.5B Instruct
- Dataset: GSM8K (grade-school math word problems)
- Method: GRPO (the algorithm from DeepSeekMath / R1) with multi-reward (format compliance + answer correctness)
- LoRA target: all seven projection modules per layer (q/k/v/o/up/down/gate). 28 layers × 7 = 196 adapters total
- Training: 1000 steps, batch=4, K=4 generations per prompt
- Profiling: logged the per-layer gradient L2 norm at every step. 392,000 data points across the run
For each rank-allocation strategy, I kept the total rank budget fixed at 896 (= 28 × 32, the uniform baseline). So same parameter count, just distributed differently.
What happened
| Strategy | Range | Params | GSM8K Acc |
|---|---|---|---|
| Base model (no LoRA) | — | 0 | 66.0% |
| Reduced 70% | r=12–31 | 25.8M | 65.0% |
| Random | r=16–48 | 36.9M | 67.5% |
| Proportional (gradient-aware) | r=20–40 | 36.9M | 70.0% |
| Uniform (r=32) | r=32–32 | 36.9M | 74.5% |
Uniform won. By 4.5 points over the gradient-aware proportional allocation that “should” have been the optimum.
The interesting thing: gradient-aware did beat random. The signal is real — proportional knew which layers were hotter than random did. But it still lost to uniform. Knowing the signal didn’t help.
What’s going on inside GRPO
First weird thing: the gradient landscape under GRPO is far flatter than what people report under SFT.
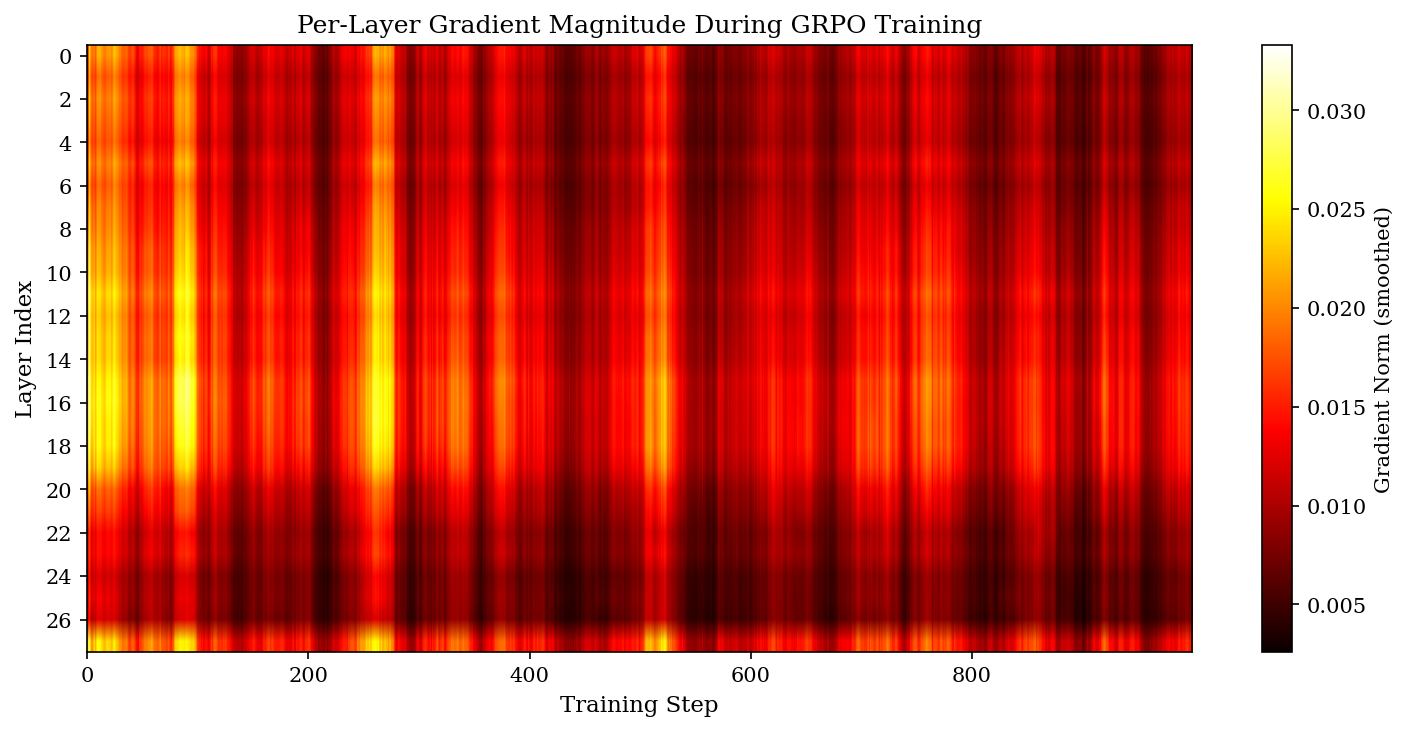
Hottest layer (15) carries 4.68% of total gradient. Coldest layer (26) carries 2.15%. Max-to-min ratio: 2.17x.
Compare that to ILA’s findings under SFT, where the top 30% of layers carry >80% of the signal. Under GRPO, the top 30% carry only ~36%. The signal is spread out — every layer is doing work.
Second weird thing: the importance map is rock-stable across training. Early-vs-late training correlation is 0.962. So the flatness isn’t an averaging artifact over noisy phases. It’s a structural property of how GRPO distributes its learning signal.
So one explanation for the negative result writes itself: under SFT there are genuinely idle layers whose capacity you can safely redistribute. Under GRPO there aren’t. Reduce a layer’s rank from 32 to 20 and you’ve broken something the model was relying on.
But there’s something stranger going on.
The amplification effect
I profiled gradients during every run, not just the uniform baseline. Here’s what the proportional run looked like vs uniform:
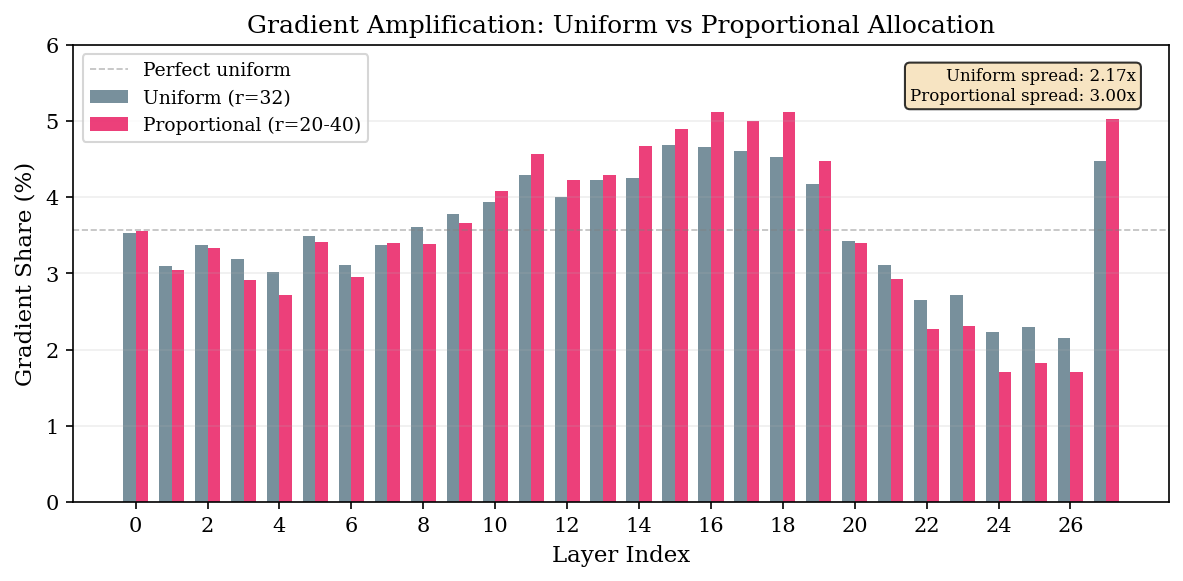
The spread widens. Uniform: 2.17x max/min. Proportional (same total budget): 3.00x. Reduced: 3.57x.
Hot layers given more rank absorb more gradient. Cold layers given less rank go quieter. The allocation creates a positive feedback loop — the rich get richer, the poor get poorer.
I ran the random allocation as a control to check whether this was just gradient-following gradient. Layer 1 is normally one of the coldest layers (3.09%). Random gave it rank 48. Its gradient share jumped to 4.21% — making it the second hottest layer in the network. Layer 15, normally the hottest, got rank 24 in the random allocation and dropped from 4.68% to 3.98%.
The correlation between allocated rank and gradient shift is 0.972 for random, 0.946 for proportional.
Read that again. Even when you allocate rank with no relation to gradient importance whatsoever, the gradient follows. Rank determines gradient importance, not the other way around.
This is the part I didn’t expect, and it has uncomfortable implications for the entire profile-then-reallocate paradigm. The “important” layers your profiling identifies aren’t intrinsically important — they’re whatever layers happen to have rank to express themselves through. Move the rank, and the importance map moves with it.
A debugging note: PEFT’s silent wildcard
About halfway through this work, my proportional run had 34.6M params instead of the expected 36.9M. Something was wrong but no errors were thrown.
I had set up rank_pattern like this:
rank_pattern = {
"model.layers.15.*.q_proj": 40, # nope
...
}
Turns out PEFT’s rank_pattern doesn’t treat * as a glob. It’s a regex match on the full module path, and * means “zero or more of the previous character.” So model.layers.15.*.q_proj matched essentially nothing in the actual module tree, and every module silently fell back to the default rank.
Fix: use exact paths.
rank_pattern = {
"model.layers.15.self_attn.q_proj": 40,
"model.layers.15.mlp.up_proj": 40,
...
}
Confirmed by inspecting actual LoRA matrix shapes after init. If you’re doing non-uniform LoRA with PEFT and your param count is suspicious, this is probably why.
What I’d take from this
Don’t naively port SFT-era rank allocation to RL training. The two regimes have qualitatively different gradient structures — flat under GRPO, peaked under SFT — and the techniques that exploit one don’t transfer.
The amplification effect also means static profiling can’t be the answer for RL. Whatever you measure during a uniform-rank run is going to shift the moment you reallocate. If adaptive rank is going to work under RL, it probably has to be dynamic — adjusting continuously during training, AdaLoRA-style, rather than committing to a fixed allocation upfront.
The good news in the negative result: uniform is fine. It’s also the cheapest thing to do.
The full paper is going up on arXiv shortly (submitted under cs.CL). Code is at github.com/yashsawant22/adaptive-lora-rank-grpo. This work was submitted to the CoLoRAI workshop at ICML 2026.